

Designing digital services that utilise AI is challenging. We need to understand what AI is good for, and we need to gain first hand experience in designing with AI. This post discusses what we have learned so far when using the new Large Language Models, such as OpenAI GPT especially for healthcare applications.
Learning to use large language models
The whole community of designers and developers are currently learning how to use large language models efficiently. This is a fascinating process to watch and experience. We need to have a solid understanding and experience of the new technology so that we can include it in our designer’s toolbox. Otherwise, we will resort to more traditional design patterns that we know will work.
This exploration is taking place everywhere right now. The internet is full of discussion and new application trials using GPT and variants. For example, you can find lists of applications and services built on top of the new AI engines posted on LinkedIn. In this post I will discuss some of our trials and proposals how LLMs can be used in one our focus areas, healthcare.
You don’t need to train GPT
What makes GPT very different to many other AI systems is that it is a “foundation model”: it doesn’t require any training before you take it in use. GPT3 was trained with 175 billion parameters or 800 GB data, and the newer models with much, much more. Therefore, it does not suffer from the limitations of many AI solutions that need a lot of training data beforehand: it can be a relevant user interface solution right from the start.
This removes the first and primary blocker of using AI and machine learning algorithms in your designs. Earlier, and also when using other models than foundation models, you needed to collect lots of training data for your service. Sometimes this simply isn’t feasible: the training data is not available.
You need to train yourself to use GPT
GPT is a language model, and it is operated by language. It is quite different from what designers are used to. It takes some time to learn how to construct appropriate requests to the model. This is such an emerging distinct skill set that it has already been given a name: prompt engineering. Just like it is important for a designer to understand the basics of the technologies that we are designing for, we need to understand enough of prompt engineering in order to have a good intuition on what is possible and what is difficult.
I have had the luxury in working together with some AI experts who use OpenAI via the APIs instead of the chat interface, which means that we have been able to integrate the technology in user interfaces of trial services. Seeing GPT in action truly exposes its numerous strengths but also reveals the weaknesses.
We have also been able to explore different ways of adjusting the prompts to converse with GPT, such as limiting the expected responses (e.g. returning boolean values) and using the temperature value to limit the amount of creativity that GPT uses when creating the responses.
Adjusting the temperature is important because our applications are mostly about summarising and categorizing existing information, and we don’t want the model to start creating too much random noise in the results. We don’t want it to start imagining anything.
LLM goes well with healthcare
Currently we are exploring how to use GPT in healthcare and social services. Both of these domains create and maintain lots of written records.
Healthcare is a fruitful domain for large language models. LLMs are not suited for logical deduction or extrapolating the future: I wouldn’t let them make the final diagnosis based on the patient’s symptoms. On the contrary, they are at their best in making summaries of existing information. In healthcare, there is a vast body of knowledge and research results, resulting in databases and journal articles around the world. The large language models can be really useful for healthcare professionals to sift through this vast amount of information and make it digestible.
Free-form text in the patient records is very effective in conveying rich nuanced information to other specialists in the same profession, but it is not suitable for secondary use of the data, such as analytics and statistics. It would be really helpful if we could either automatically extract structured data (e.g. with SNOMED CT codes [5]) from the textual descriptions, or even better, support the professional with interactive solutions to confirm the right codes at the time of writing the patient record entries.
Example: symptom checker
We have been exploring the possibility to use LLMs in services that are intended for ordinary people to understand the symptoms they are suffering from. The purpose of these services is twofold:
- Give advice if people can treat their symptoms at home or if they should contact a professional
- Send the symptom information to the healthcare unit, so that they can forward people to talk to the right specialist
Traditionally, symptom checkers consist of web forms that people need to fill in (see Figure 1). These forms can be really long and tedious to fill in, and they require a relatively good understanding of the symptoms and the language used in the forms to answer the questions correctly. For examples, see e.g. Mayo Clinic or WebMD.
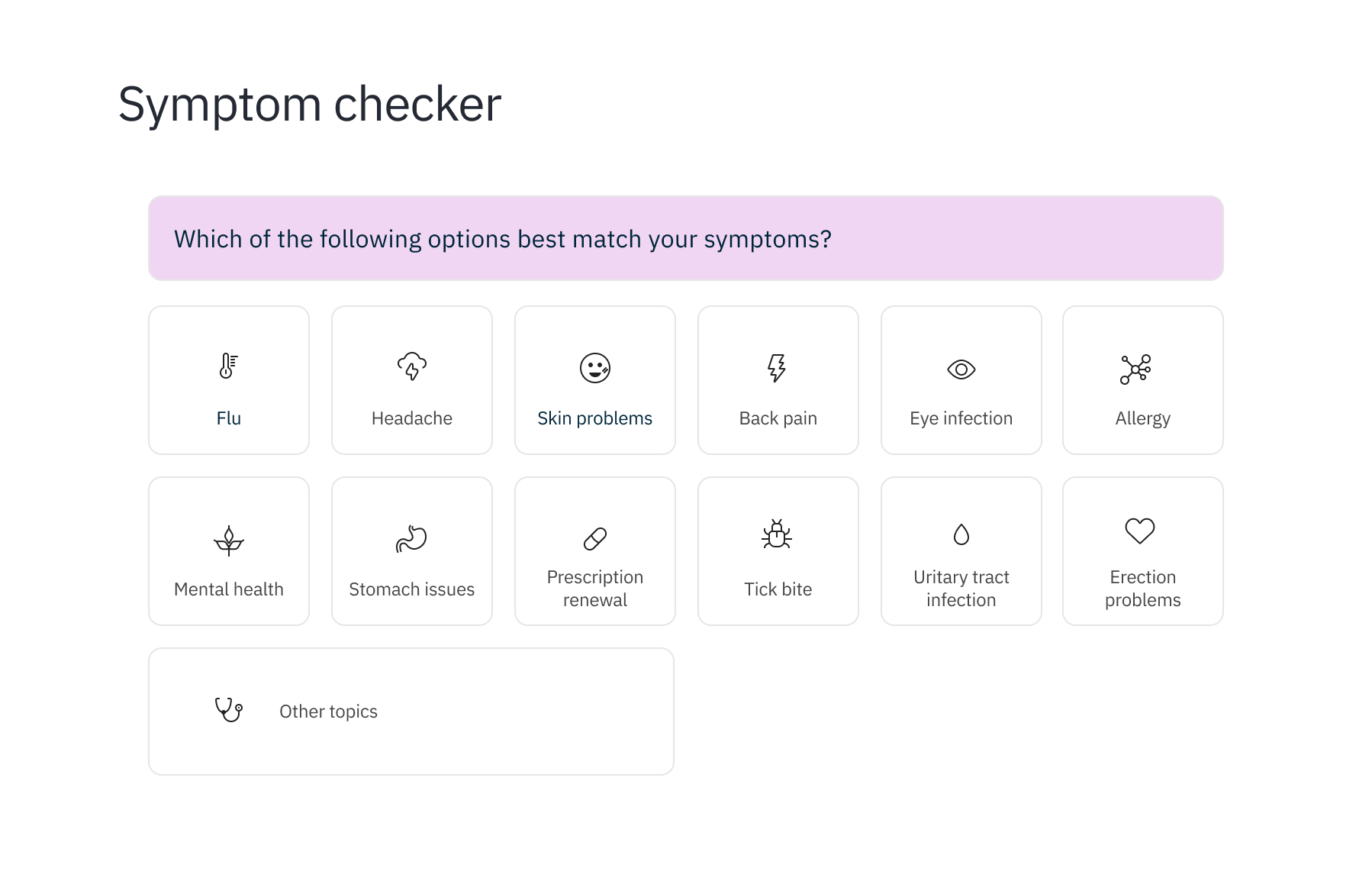
In our solution, we wanted to avoid these long and tedious web forms. Instead, we simply ask people to describe their symptoms in their own words (see Figure 2). We then use GPT to analyse the text to extract the details of the symptoms so that we can give reliable feedback about possible treatments, and summarize the descriptions for the professionals.
In case we find out that the description is lacking some relevant piece of information, we can use similar but more focused prompts to ask for more information from the user, either still as free-form text or, when nothing else helps, with web form elements such as buttons or check boxes.
Based on our experiments, we have proven that we can get high quality data from the free textual input using GPT. This takes some effort in adjusting the prompts. We are also constantly improving our skills in the art of prompt engineering.
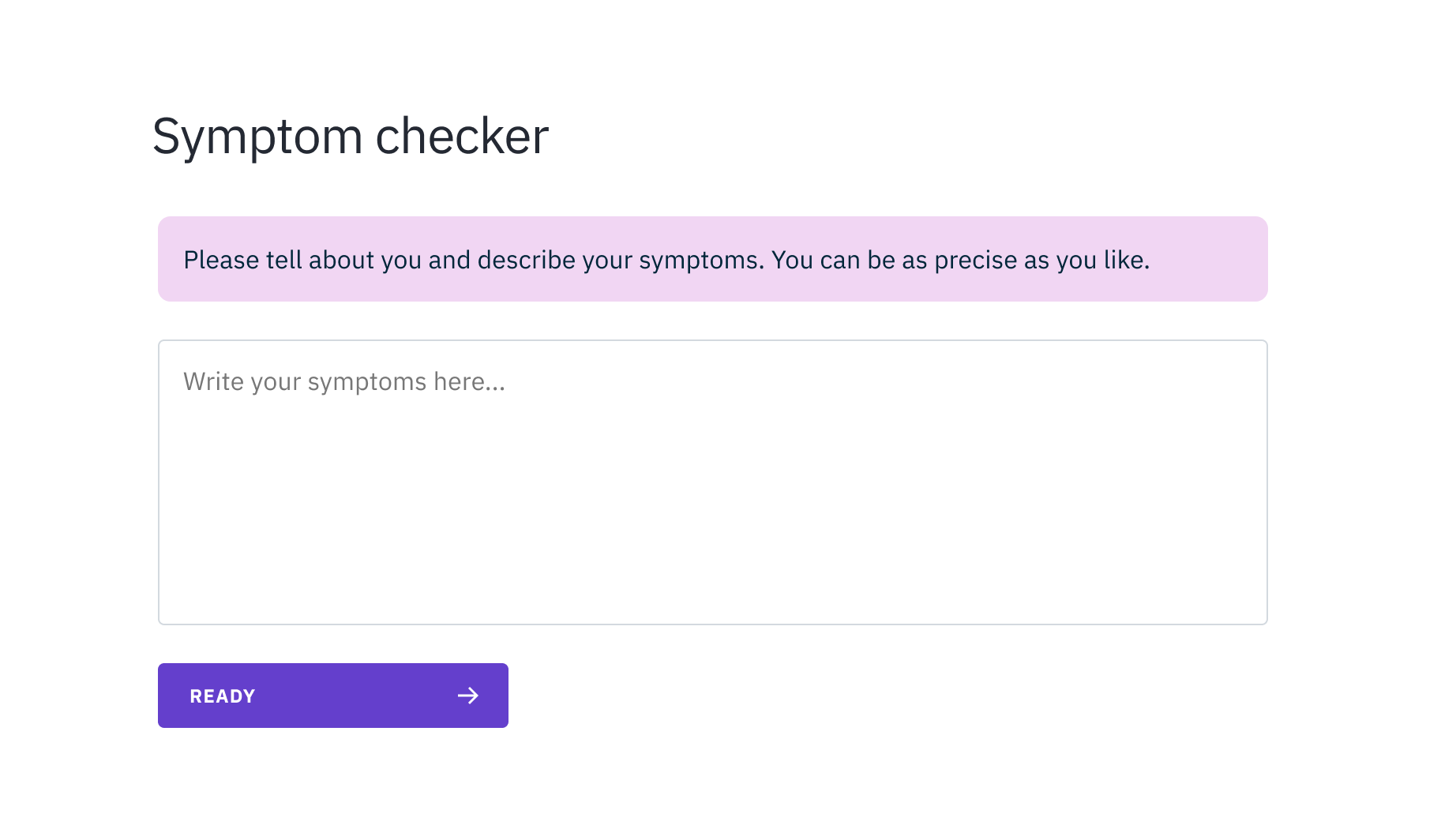
In this way, entering the symptoms feels much more natural and friendlier; people are not restricted by a strict web form for entering their texts. In addition, the textual information can provide the healthcare professionals additional hints about the symptoms in richness that goes beyond check boxes and radio buttons.
A few hurdles and we’re ready to go
There are still some hurdles before we can use LLMs with electronic health records. They contain private information that we must keep strictly secure and confidential. There are legal restrictions that limit the use of currently available APIs for processing the information.
The response times for the queries are not yet fast enough that they could be used in real-time when healthcare professionals are typing or dictating patient records. We expect that these limitations will be overcome soon — the last ones being the legal hurdles that always take the longest to change.
Added bonus: equality
One very interesting property of the LLMs like GPT is that they are agnostic to the language that the users of the services prefer to use. We can query GPT in practically in any language they prefer — or even mix languages. The prompts in our back-end that send requests to the GPT API are in English, but we don’t need to touch them in any way: they work just as well for any language people want to use. To our surprise, our symptom checker (Figure 2) could take almost any major language and provide consistently similar results.
This is especially interesting for public services where we want to provide a good experience for people independent of their preferred language.
And that’s not all
This example of the symptom checker is just one of the applications that we are working on. We want to make it easier for the healthcare professionals to enter structured information, to query research results and medical databases, assist in writing patient records, help patients understand medical terminology, etc. All this is possible with the new LLMs: they are perfectly suited for tasks that find, categorize, summarize, or expand textual information.
As a designer I appreciate that the new technologies support using people’s own language in free-form text. It is a very humane approach.
Resources:
[1] “AI is a solution in search of a problem”, Panu Korhonen
[2] “Let’s get AI in the designer’s toolbox”, Panu Korhonen
[3] “Prompt engineering”, Wikipedia
[4] “Foundation models”, Wikipedia








